读书分享:为什么学生不喜欢上学

大家好, 今天分享一本书, <<为什么学生不喜欢上学>>. 这是本写给教师的认知心理学方面的科普, 目前豆瓣热门教育学排名第一. 这本书主要是介绍思考的工作原理, 以及根据这些原理制定合适自学和育儿策略.

让我们先从第一个事实开始:『人类的大脑并不擅长思考』. 实际上, 我们的大脑能做很多事, 擅长做一些事, 但是思考能力和其他能力比起来, 明显不是大脑的长项.

举个例子, 我们的视觉一秒钟就能准确识别验证码, 但是计算机到现在也不能读取数据. 我们的听力对计算机可以做到『以我为准』, 计算机语音识别结果和人工不一样, 基本都是计算机错. 人类在驾校培训三个月基本可以上路开车, 但无人驾驶发展了这么多年, 还是做不到 L4 级自动驾驶. 事实上, 大脑的视觉, 听觉和运动能力都是碾压计算机的存在. 但是, 谁能在 1 秒内回答:20187×33652 等于多少?
和我们的视听能力相比, 我们的思考能力是相当缓慢, 费力且不可靠的. 实际上, 如果我们每一个决策都要思考的话, 我们会发现日子完全没法过. 就像那个经典笑话讲的那样:
隔壁的蜈蚣突然出不了门了! 咋回事? 它在思考出门先迈哪只脚
所以问题来了, 如果我们的大脑不擅于思考, 但我们每天上班, 去超市买便宜菜, 写代码做技术选型, 这些看起来都需要思考. 那我们平常是怎么过的呢?
答案是:当我们能侥幸完成任务的时候, 我们就不会去思考, 而是依赖记忆. 我们面临的大多数问题都是已经解决过的, 因此我们只要重复之前的步骤就可以. 通常我们认为记忆存储的是过去的故事和事实性知识. 但实际上, 记忆里还有我们行动的策略:回家时在哪里转弯, 锅里的水烧开了怎么办等等. 举个例子, 我们在食堂吃饭的时候, 就不会考虑拿筷子的位置, 要夹的菜, 吃饭时筷子要抬多高等问题, 而是直接就吃, 完全不用思考.
总结一下, 大脑有两种方式可以用来免于思考.
首先, 一些最重要的功能, 比如视觉和行动, 不需要思考. 其次, 我们倾向于用记忆而不是思考指导行动. 而且, 除了使用记忆辅助生活, 大脑为了逃避思考, 甚至还会主动做出改变. 举个例子:我们刚学骑车的时候注意力高度集中, 战战兢兢唯恐摔倒. 但练习多了之后, 我们不光骑车时不用动脑筋, 还能边听歌边骑车, 而且还能一路骑回家.
也就是说, 我们的大脑不光不擅长思考, 而且还会努力避免思考. 那这样再看"学生为什么不喜欢上学"是不是就好理解些了?
不过幸运的是, 尽管我们不擅长思考, 但是我们其实喜欢思考. 人类天生就有好奇心, 也会不断寻找可以进行思考的机会. 只是因为思考很难, 所以需要条件合适才能继续, 否则我们会很快放弃思考这个念头.
成功的解决问题会带给我们愉悦感, 而且, 让我们快乐的是解决问题的过程. 一盘怎么打怎么输的游戏只会让我们砸键盘, 无敌密码也只会让游戏索然无味. 对我们来说, 最有意思的还是一场 1v50 险象环生历经艰险逆风翻盘的游戏. 实际上, 决定我们好奇心是否可持续的是问题的困难程度. 解决太容易的问题不会带来愉悦感, 而如果认为一个问题非常困难, 我们可能一开始就会选择放弃. 好奇心驱使我们不停的寻找新的主意和问题, 但是我们会很快分析解决问题需要多少脑力劳动, 如果太多或太少, 在允许的情况下, 我们就会停止努力.
这实际上是多数学生不喜欢上学的原因. 解决难度适当的问题当然很好, 但是如果解决的问题太难或者太简单, 学生就会感觉挫败或者无聊. 如果长期保持这种状态, 很容易理解为什么学生会比喜欢上学.
所以我们的解决方法是什么?当然我们可以选择降低题目难度让他做容易的作业, 但是得时刻记住问题不能太容易, 否则他就会觉得无聊. 哪有没有可能让思考变得容易些, 而不是降低题目的难度呢?
当然可以, 不过在提升思考能力前, 我们得先知道思考是如何工作的.
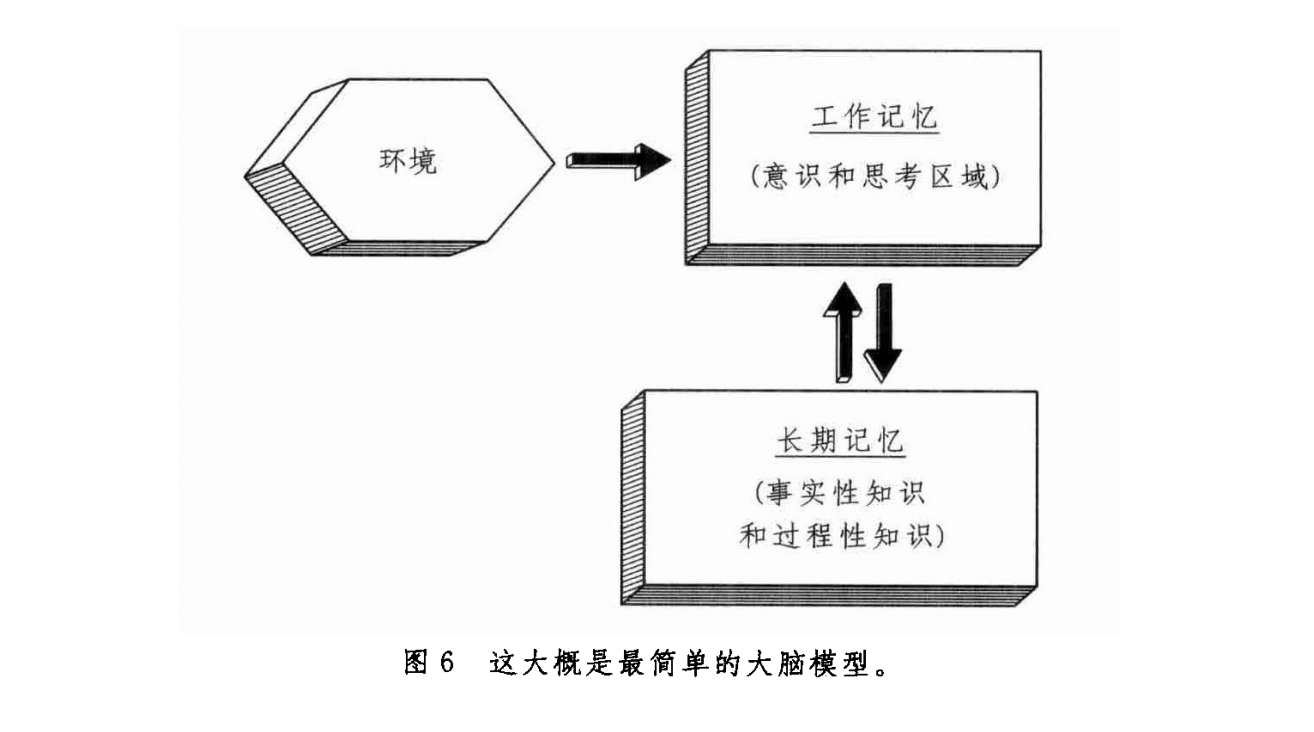
让我们从这张图开始. 这算是最简单的大脑模型. 左侧是环境信息, 右上方是大脑的工作记忆, 右下方则是我们的长期记忆. 我们思维的过程本质上是从环境和长期记忆中提取信息, 并在工作空间中进行排列组合的过程.
影响思考过程的主要是
- 来自环境的信息
- 来自长期记忆中的事实性知识
- 来自长期记忆中的规则性知识
- 工作空间的容量
已经有实验证明, 在这四个因素中, 大脑工作空间的容量是基本恒定的(7±2 个单位), 所以提升思考能力要从剩下的三项, 以及, 单位的定义入手.
实际上, 长期记忆中的事实性知识, 也叫做背景知识是加速我们思考的关键. 它可以:
- 增大工作记忆的空间容量
- 增强理解能力
- 能够加速思考过程
让我们一个一个看.
首先第一点, 长期记忆中的事实性记忆可以增大工作记忆的空间容量
看一下这个实验

10 秒钟快速记忆, 看能记住多少?大部分人只能记住七(±2)个左右, 这很正常, 因为大脑工作空间容量差不多就是这些. 那如果是这张表呢

你可能记住了更多字母, 也注意到了这些字母因为组成了熟悉的首字母缩略词而简单了很多. 但实际上, 大家注意到这两张表实际上是同样的了吗?我只是改变了换行的位置让缩略词在表二中变得更加明显.
我们刚才说过, 工作记忆容量有限, 只有 7(±2)个单位, 所以我们不能在工作记忆中记住表一里所有字母, 但是表二就可以. 这是因为, 工作记忆的空间大小不是由字母多少决定, 而是由有意义的片段决定. 如果你能记住七个毫无不相关的字母, 你就能记住七个(或者接近七个)毫不相关的单词. JAVA 在一起是有意义的, 记住它不会占用四个单位空间, 只会占用一个位置.

将环境中分散的信息片段拼在一起的现象叫做合并(组块), 它的优点是显而易见的:如果信息可以被合并, 那么我们就能在工作记忆中存储更多内容, 从而提升思考能力. 这里的关键是:合并只有在我们的长期记忆中有合适的事实性记忆时才有效, 我们只有知道 CSS 是什么后才会认为 CSS 有意义. 在表 1 中, 如果你对艺术很了解, 知道梵高(VanGogh)的名字, 你可能就会合并 VAN 这个组合. 但如果我们不知道, 那 VAN 对我们来说就是普通的字母.
像这种利用背景知识在工作记忆中组合信息的现象, 不仅应用于字母, 它可以运用于任何事情:象棋比赛中的棋局, 舞蹈家的舞步移动, 演讲家的即兴演说——说一起来一套套的等等. 实际上, 这也是过目不忘的基本原理.
第二点, 背景知识可以增强我们的理解能力.
看一下这段话
XXXX 是种具有物件概念的程式程式设计典范, 同时也是一种程式开发的抽象方针. 它可能包含资料、属性、程式码与方法. 物件则指的是类别的实例. 它将物件作为程式的基本单元, 将程式和资料封装其中, 以提高软体的重用性、灵活性和扩充性, 物件里的程式可以存取及经常修改物件相关连的资料. 在物件导向程式程式设计里, 电脑程式会被设计成彼此相关的物件
是不是不太好理解. 这段话基本能够做到每一个字都是汉字但是连在一起完全看不懂什么意思. 如果就这段话去做阅读理解题, 我们的成绩不见得能比高中生好到哪里.
但如果换成这段话呢?
XXXX 是种具有对象概念的程序编程典范, 同时也是一种程序开发的抽象方针.它可能包含资料、属性、代码与方法. 对象则指的是类的实例. 它将对象作为程序的基本单元, 将程序和数据封装其中, 以提高软件的重用性、灵活性和扩展性, 对象里的程序可以访问及经常修改对象相关连的资料. 在面向对象程序编程里, 计算机程序会被设计成彼此相关的对象
如果让我们概括这段话的中心思想, 虽然前边的 XXXX 被打码, 但是基本还是能反应过来这是在说"面向对象程序设计"方面的知识.
事实上, 这两段话是维基百科面向对象设计的简繁两种版本. 这两个版本的阅读难度对非计算机行业的同学是等同的, 但对有相关背景知识的从业人员而言, 理解简体版面向对象定义的难度比繁体版低一个数量级.
实际上, 这是一个普遍现象.
研究表明, 如果有一些相关的背景知识, 就能够更好的理解他们读到的东西. 其部分原因就在于合并. 在一个初中生内进行的研究中, 首先按阅读能力高低将学生分为两拨, 让他们阅读一篇关于棒球的短文并回答问题, 然后再根据是否熟悉棒球对结果进行区分. 结果很明显, 对棒球的知识决定了他们对故事的理解, 阅读能力的差别和背景知识比起来并不重要.
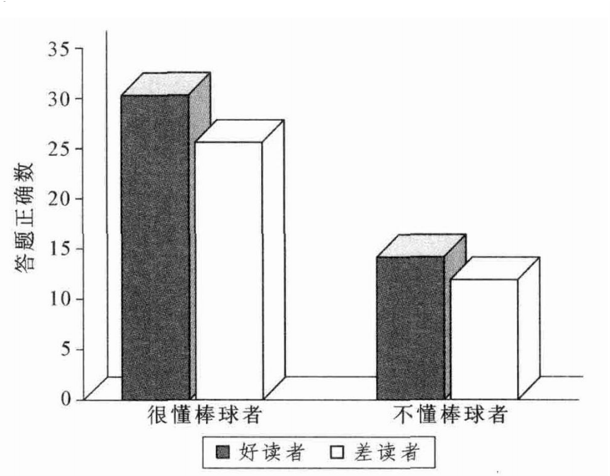
实际上, 对于阅读理解而言, 背景知识至少能在四个方面上提供帮助:
- 首先, 背景知识可以提供词汇.
- 其次, 背景知识可以帮忙填补作者论证过程中的逻辑空白. 减少阅读压力
- 然后, 背景知识可以合并文章内相关的要点, 变相增大工作记忆中的空间
- 最后, 在阅读模棱两可的句子时, 背景知识还能为之提供解释.
像刚才那一段, 如果开头点明这是在讲面向对象设计的文字, 是不是理解起来也会容易很多?
物件导向程式设计(英语:Object-orientedprogramming, 缩写:OOP)是种具有物件概念的程式程式设计典范, 同时也是一种程式开发的抽象方针. 它可能包含资料、属性、程式码与方法. 物件则指的是类别的实例. 它将物件作为程式的基本单元, 将程式和资料封装其中, 以提高软体的重用性、灵活性和扩充性, 物件里的程式可以存取及经常修改物件相关连的资料. 在物件导向程式程式设计里, 电脑程式会被设计成彼此相关的物件
然后是第三点: 背景知识可以加速我们的思考过程.
思考一个问题:在我们认为我们在进行逻辑思考的时候, 我们是真的在进行逻辑思考, 还是更多的在进行记忆检索呢?
实际上, 在遇到问题时, 我们的第一反应都是先在记忆中搜索解决方法, 如果找到一种, 我们往往会立刻使用它. 这种做法很省事, 而且大部分情况下还很有效.
我这没事 关了重开 刷新一下 重启试试
举个例子, 通常我们会认为国际象棋是一项智力运动, 选手要经过认真思考缜密推理之后最终才能决出胜负, 因此, 决定棋手差距的应该是他们的思考能力.
然而并不是. 理由是这样:
在正常的比赛中, 棋手各有一小时时间, 如果决定象棋技术的主因是思考能力, 那么, 在快棋乃至超快棋比赛中, 由于选手将不会有时间进行思考, 所以必然会造成部分依靠思考能力的选手排名下降. 也就是说, 理论上会出现这种情况:
- 在标准比赛中, 决定棋手排序的是棋手的思考能力
- 在快棋比赛中, 由于选手没时间思考, 所以决定棋手排序的应该是其他因素, 谁这个因素强, 谁排位高.
- 这两种比赛模式下, 选手的排位顺序会有一定的区别.
然而, 实际上, 最好的选手在快棋比赛中依旧是最好的, 排名第二的依旧排名第二. 事实上, 象棋选手之间的差距是记忆带来的. 在比赛中, 象棋选手首先对整盘棋迅速做出判断, 决定哪一部分是最需要立刻做出反应, 以及自己和对方的弱点, 然后走棋. 这一过程依赖于棋手对相似棋局的记忆, 而这是记忆检索过程, 只需要几秒的时间. 检索完成后大大缩小了棋手可能落子的范围, 然后棋手才会开始相对较慢的思考过程, 从几种备选方案中进行选择. 这就是为什么最好的棋手在快棋赛中也能胜出的原因. 心理学家估计顶级象棋选手可能在长期记忆中拥有五万局棋局记忆. 因此, 背景知识在象棋比赛中也起到了决定性作用----即使我们通常认为它是典型的逻辑思考游戏.
Ok, 到目前为止, 我们论证了背景知识可以
- 增大工作记忆的空间容量
- 增强理解能力
- 能够加速思考过程
所以自然而然会有一个问题:背景知识这么有用, 那该怎么获取呢

那让我们一起来看一下, 积累背景知识的四个途径.
增强记忆:记忆是思考的残留
背景知识的积累实际是记忆, 但是记忆本身却很神奇. 我们看过一遍电视剧往往能记住里边大部分的细节, 但听完一堂课后却往往什么也不记得. 如果要讨论我们会记住什么, 我们得先看看我们为什么记不住.
来看这张稍微复杂点的大脑示意图. 遗忘有四种可能性.
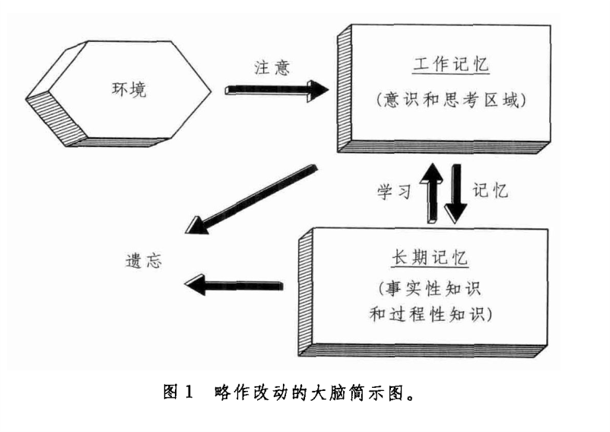
首先, 环境信息必须要先进入工作记忆才有机会进入长期记忆. 如果没有集中注意力, 即使环境中存在信息, 我们也不会记住. (比如没人记得我的手是放在键盘上还是触摸板上), 遗忘的第一种可能是:这些信息从来就没有进入过我们的大脑. 这种情况比较好处理, 集中注意力就可以
信息不仅可以从环境中进入工作记忆, 也可以从长期记忆中进入, 也就是回忆. 遗忘的第二种可能是我们不能从长期记忆中找回信息. 第三种可能则是长期记忆中的信息本身就不存在. 这两种情况的原因和处理方案我们后边再讲. (理解其实是记忆)
第四种可能则是, 我们花了精力, 事情在工作记忆中停留了一会儿, 却不能进入长期记忆. 而且很尴尬的是, 有时候我们并不想记一些东西, 但是却记得很清楚.
今年过节不收礼, 收礼只收…
实际上, 教育研究的核心问题之一, 就是搞清楚怎么才能让事实性知识从工作记忆进入长期记忆. 我们可以接受不付出注意力就不能学到知识, 但为什么我们付出注意力之后, 有时候能学到知识, 有时候却不能?记住事情, 除了注意力还需要什么?
首先能想到的是, 我们能记住带来情感反应的事. 实际上如果让我们回想印象最深刻的记忆, 我们往往会提到和情感相关的事件. 比如第一次约会或者参加高考啥的. 研究证明, 情感对记忆的影响确实存在, 但是情感需要足够强, 才能对记忆有影响.
另一个对记忆有帮助的因素是重复. 这里的经典案例可能就是"今年过节不收礼", 或者"恒~ 源~ 祥~, 羊羊羊". 重复很重要, 但不是所有的重复都有效, 有些内容可能重复无数次, 却还是记不住. 比如说, 我们平常吃的, 是恰恰瓜子, 还是洽洽瓜子, 还是哈哈瓜子?

只有重复是不够的, 而且只有想记住的愿望也是不够的. 在一个经典实验中, 屏幕上每出现一个单词, 被试都要做出简单判断. 一部分人判断这个词是否含有字母 A 或者 Q, 另一部分要判定这个词是让他们想起愉快的事还是不愉快的事. 实验的关键是, 看到词表后, 一半被试会被告知他们对词表的记忆会被测试, 另一半没有.
这个实验的重要发现之一是, 事先知道会被测试并不会提高被试者的记忆. 其他有奖励版本的实验也说明, 告诉被试记住单词就有报酬也不奏效. 所以, "愿意记住"对提高记忆的效果几乎为 0.
但是, 这个实验还有一个更重要的发现:判断单词让他们想到是愉快还是不愉快的那组, 记住的单词几乎是含有 A 或 Q 的两倍.
这两者之间的区别在于, 判断 A 或 Q 只需要走逻辑就行, 但是判断单词唤起的情感却需要思考. 事实上, 我们想什么就会记住什么. 记忆实际上是思考的残留物.
这其实是一种非常合理的建立记忆系统的方法. 大背景是我们的大脑容量不可能储存所有事, 所以我们大脑选择这样判断事情的价值:如果我们不常思考一件事, 我们可能不会需要再想它, 所以可以丢弃. 但如果我们真的再想一件事, 以后我们还可能会从同一角度在想一次, 所以这是有意义的事, 需要被记下来.
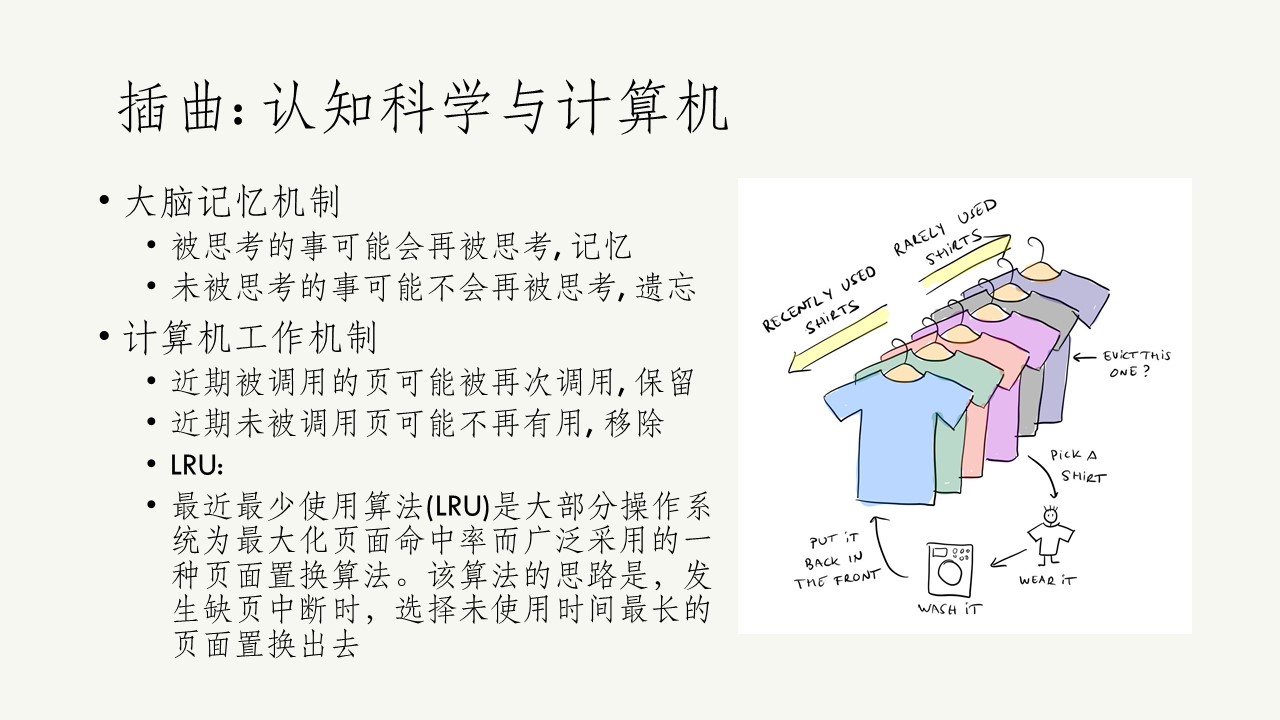
这里插一句, 其实认知科学和计算机科学非常接近. 像这种记录工作记忆中经常被思考的部分, 没被思考过的部分过期自动淘汰这种策略, 有没有让大家想起来一种算法.
最近最少使用算法(LRU)是大部分操作系统为最大化页面命中率而广泛采用的一种页面置换算法. 该算法的思路是, 发生缺页中断时, 选择未使用时间最长的页面置换出去
增强理解:理解其实是记忆
刚才我们描述了事物是怎样进入记忆的, 但我们其实有一个假设, 假设进入记忆后的事物可以被学生理解. 但这显然不现实. 我们对于新概念常常难于理解, 尤其是非常新颖的, 不能联系到其他已知概念的内容. 在这点上, 认知科学会给我们什么建议呢?
答案是:我们应该通过联系已知的概念来理解新概念. 这很容易理解. 这有点像我们接触到生词时的情景. 如果我们不知道"xswl"的意思, 百度一下, 发现是"笑死我了"的拼音缩写, 因为我们知道"笑死我了"的意思, 所以我们自然就能知道"xswl"的意思.
一般来说, 理解新事物需要依赖于联系已知的事物. 但是不是建立起联系就能真正的理解这件事?比如说:

标尺上的数字之间的关系只有四种可能 名义尺度:每一个类别有一个名称. 比如球员球衣上的号码和他们的水平没有任何关系 顺序尺度:类别按照大小或者多少的程度排序, 但给定位之间具体差距定序的尺度无法反映. 比如赛马时, 我们知道第一名比第二名快, 但不知道快多少 等距尺度:类别不仅有顺序, 而且还是等距的. 比如温度, 10° 到 20° 之间的差距和 80° 到 90° 之间的差距时一样的. 等距尺度的 0° 时任意值. 摄氏 0 度不代表没有温度 比例尺度:比如年龄, 有真正的零点. 0 岁代表没有年龄.
正确的理解其实是记忆. 因为理解要求我们能在长期记忆中取出正确的概念放入工作记忆里, 而且, 这些记忆中概念的正确特征必须被用到. 如果我们理解顺序量表和等距量表之间的差别时, 只回忆起温度计和赛马是不够的. 这些例子可以让概念进入工作记忆, 但是我们需要确保我们是在用正确的方法进行比较. 而我们知道, 理解其实没那么简单. 我们知道的是比之前多一点, 但是我们的知识不够深, 也没有信心辨识新例子里的计量标度, 比如尺子上的厘米刻度是什么标度类型
实际上, 如果想加强理解, 我们需要讨论两个问题: 首先, 即使我们"懂了", 这个懂也有深浅之分, 有人理解的很浅显, 有人理解的很透彻. 其次, 即使我们在当下懂了, 这些知识也未必能在其他环境中得以运用. 这个问题我们分成两个角度讨论:表面理解和不能活用.
表面理解分为几个程度:最差的情况是只会死记硬背. 比如按字母背诵 LRU 算法(还记得这个算法吗, 最近最少使用算法, 我们的大脑通过这个算法决定记下来什么记不住什么). 好一点的情况是看到题目能写出来 LRU 算法. 基本来公司面试的同学都能做到这一步. 但也就到此为止了.
但对于一个拥有深层知识的同学来说, 它对于学科知识不仅知道的多, 知识点之间也能够连接的更加充分. 它不仅了解每一个部分, 还看得到全景. 这种认识能让他把知识应用到很多不同环境中, 用不同方式进行讨论. 比如我们在工作中使用 LRU 算法, 但是有没有考虑过算法其实在我们的生活里也经常用到?比如, 我们在放衣服时, 实际上就在用 LRU 算法管理我们的衣架:最常用的衣服放床上, 起床就穿. 次常用的衣服放衣柜里, 有需要时拿出来穿. 最不常用的放收纳箱里, 季节到了在拿出来或者直接扔掉. 实际上真的有人在学习算法的之余还用算法对自己的生活做规划, 而且还写了本书, 大家有时间可以看下这本.
但事实上, 深层知识表示理解所有事情, 包括抽象的概念, 实际的例子和他们之间的联系. 难于理解深层知识是正常的, 因为深层知识本身就比表面知识更难获得
另外一点是, 当我们理解了一个抽象的概念, 我们希望这些知识能够迁移. 也就是将已有的知识应用在新的问题上.
比如说这两个问题
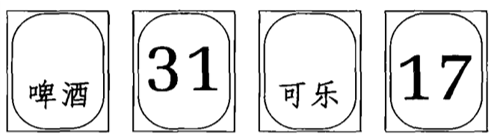
想象你是酒吧门口的检察人员. 每张卡片代表一位顾客. 一面是年龄, 一面是所点的饮料. 你需要遵守这条规则:只有年满 18 岁的顾客才能喝啤酒. 你的工作是检查这四个人有没有违规. 需要翻得卡片越少越好. 你应该翻哪几张卡片

每张卡片都是一面字母, 另一面数字, 规则是, 如果一面有元音字母, 另一面必须是个偶数. 你的工作是检查这四张卡片是否合乎规则, 翻得卡片越少越好. 你应该翻那几张卡片.
这两个问题叙事方式----心理学中称为表层结构不一样, 但解题步骤相同, 也就是说, 他们拥有着相同的深层结构. 显然, 表层结构对解题本身并不重要, 我们期望会解第一题的同学也能解第二道题, 因为深层结构才是关键.
但事实上, 大部分人没法进行知识迁移. 因为我们读到或听到话语时, 会利用已有知识进行理解. 而且, 我们的大脑会假设我们读到的新事物和前面读到的事物有关. 这可以让我们理解的更快, 更顺利. 但是这也让我们更难辨别问题的深层结构. 在读第一个问题时, 我们抽取的背景知识是:啤酒, 酒吧, 未成年人. 而第二个问题中, 我们抽取的背景知识是字母, 数字, 元音, 偶数. 自然难以建立联系.
解决的方法看起来简单, 似乎在读题时直接告诉我们思考深层结构就可以. 但问题是, 一方面深层结构不容易被发现, 另一方面一个故事可能有无数深层结构, 怎么理解看起来都有道理. 不过, 成年人往往能够利用经验做到一定程度的知识迁移. 这种迁移不容易发生, 但是有办法提升发生迁移的概率.
这种方式, 就是练习.
增强练习:没有充分的练习, 你不可能精通任何脑力活.
我们认知系统的瓶颈市同时处理几件事的程度. 例如, 心算 16x9 不难, 但心算 16788x89621 则几乎不可能. 他们使用的方法虽然一样, 但是大脑工作记忆中没有足够空间存放后者的中间步骤. 对这一问题, 练习是最重要的窍门之一. 因为它减少了大脑活动所需要的空间.
实际上, 没有充分练习, 我们不可能精通任何脑力活.
工作记忆空间有限是人类认知的基本瓶颈. 虽然有研究显示, 工作空间大的人推理测试得分会更高, 但是, 就当下认知科学的研究显示, 工作记忆的空间大小是固定不变的.
不过, 正如我们之前所说, 我们可以通过合并的方式将几个事物视为一个单元, 从而在工作空间中储存更多知识. 但是存储的前提是我们得有对应的知识. 如果我们知道"N, A, R, U, T, O"是火影忍者的英文名的话, 我们就能合并成一个, 否则这就是六个独立的字母.
所以, 摆脱工作记忆有限空间的方法第一个是增加背景知识.
第二个方法则是通过反复练习, 将思维过程自动化.
比如说, 下面这段话中, 每个数字代表一个字母, a=1, b=2, c=3, 依次类推.
7 4 11 11 14 22 14 17 11 3
理论上讲, 看数字和看字母其实是等价的, 但由于我们没有进行过阅读数字的练习, 所以我们被迫把工作记忆空间浪费在转换上, 导致阅读效率直线下降. 上边这两行写的是 helloworld. 但我估计没人能翻译过来. 这其实也是英语不好的人做阅读理解时的体验.
对应的, 当我们通过练习将思考过程转为自动化过程后, 之前占用工作记忆空间的过程现在占的地方很少, 那么其他过程就有空间了. 而且这个练习是分层次的:我们只有将需要占用很多工作空间的基本步骤自动化之后, 才能腾出空间去进行下一层次的思考. 就像学习编程一样, 一开始主要精力用在保证代码中间没有语法错误, 可以编译通过. 等这关过了, 才能去研究使用项目文件结构, 然后才能是整体项目架构.
结语:智能上的差异可以通过持久努力进行改变
最后, 总结一下今天分享的内容:
虽然思考不是大脑的强项, 但是我们的大脑喜欢思考.
我们的思考速度受信息提取速度和工作记忆空间大小的限制.
理解信息需要将现有信息和我们的背景知识进行连接, 因此, 更多的背景知识可以增强我们的理解能力, 加快信息摄入速度.
同时, 在背景知识的支持下, 我们还能对信息进行组合, 从而变相增大工作记忆空间的大小.
背景知识其实就是长期记忆中的事实性知识和规则. 研究显示, 记忆是思考的残留物, 也就是说, 在记东西时思考或者想象有助于记忆.
而理解的本质其实也是记忆, 理解分为表层理解和深层理解.
深层理解不容易做到, 属于高层次思考过程. 需要勤于练习, 将低层次思维过程自动化之后, 才能进行思考.
最后留一个思考题.
在美国的学生中有四年级掉队现象. 表现为家庭背景较差的学生在学前班到四年级之前阅读能力表现正常, 但四年级之后突然无法跟上同龄人, 之后几年越加严重.
已知, 四年级前阅读指导重在教育学生如何利用印刷符号读出正确的单词.
四年级后大多数学生已经熟练掌握发音, 因此教学重点转向着重理解.
那么, 是否可以用知识面(背景知识)理论解释这个现象, 如果没有外部干预, 孩子在四年级掉队后是否可以扭转.
如果我们是家长, 我们应当采取什么策略, 扭转这种情况, 为什么